
![]()
A few weeks ago I wrote about how easy it is to set up Tintri Synchronous Replication groups. Last week I was at some customer sites not only discussing the feature but talking about various use cases for it. There are a few that came to mind but I wanted to show one basic, yet viable solution. The idea stemmed from a simple question from a customer that stated “If one Tintri is so awesome, and we love it, What can I do with two Tintri’s?” It’s funny how such a simple question can spawn a 45 minute white board working session. Here is a little bit about one of the uses cases we talked about. The concept is building a basic pod based architecture to allow for easier operational maintenance and changes.
“Why are two Tintri’s better than one?”
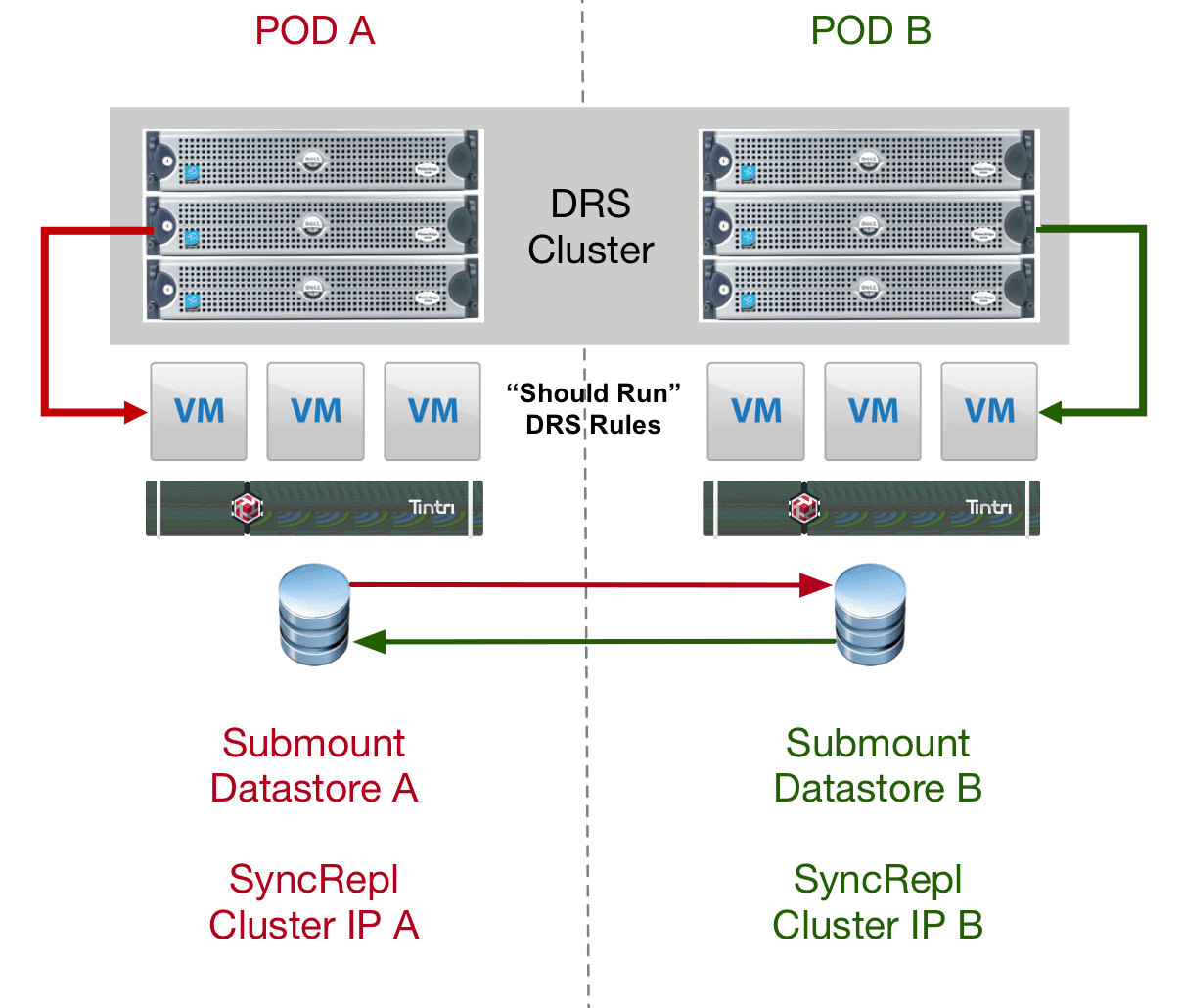
If you refer back to the article about setting up Synchronous Replication the basic concept is that the two Tintri units are accessed via a cluster IP that resides on the data ports. You can create multiple cluster IP addresses which can enable this pod based architecture design. The basic components would be two racks configured identically. For the purposes of illustration here is what I will use going forward
- 3 vSphere hosts per rack
- 2 top of rack switches connected per This Article
- redundant power
- 1 Tintri EC6000 per rack
The concept here is to build a vSphere DRS cluster than spans the two racks. As you can imagine this could also be done across campus or across town should the latency support it. The idea shown below setup simply with two Tintri cluster IP’s each running on the local side Tintri as the primary. These are presented as separate single datastores to the cluster. So in effect the cluster in this case would see TWO simple NFS datastores. The are hosting virtual machine for each half of the cluster using DRS ‘Should Run’ rules to insure they try to stay locally on their half of the cluster. This provides locality to the hosts on that side of the cluster. All the while both Tintri Sync Replication groups are replicating back and forth.
 Once this is configured and we need to do any kind of POD based maintenance we can put the hosts in one cabinet into maintenance mode. Due to the “Should Run” run in place, it will allow these to be evacuated to the other hosts in the cluster. If we only put a single host in maintenance mode they would try to remain on the left side. This is also assuming you have architected the POD to take a one-half outage for this purpose.
Once this is configured and we need to do any kind of POD based maintenance we can put the hosts in one cabinet into maintenance mode. Due to the “Should Run” run in place, it will allow these to be evacuated to the other hosts in the cluster. If we only put a single host in maintenance mode they would try to remain on the left side. This is also assuming you have architected the POD to take a one-half outage for this purpose.
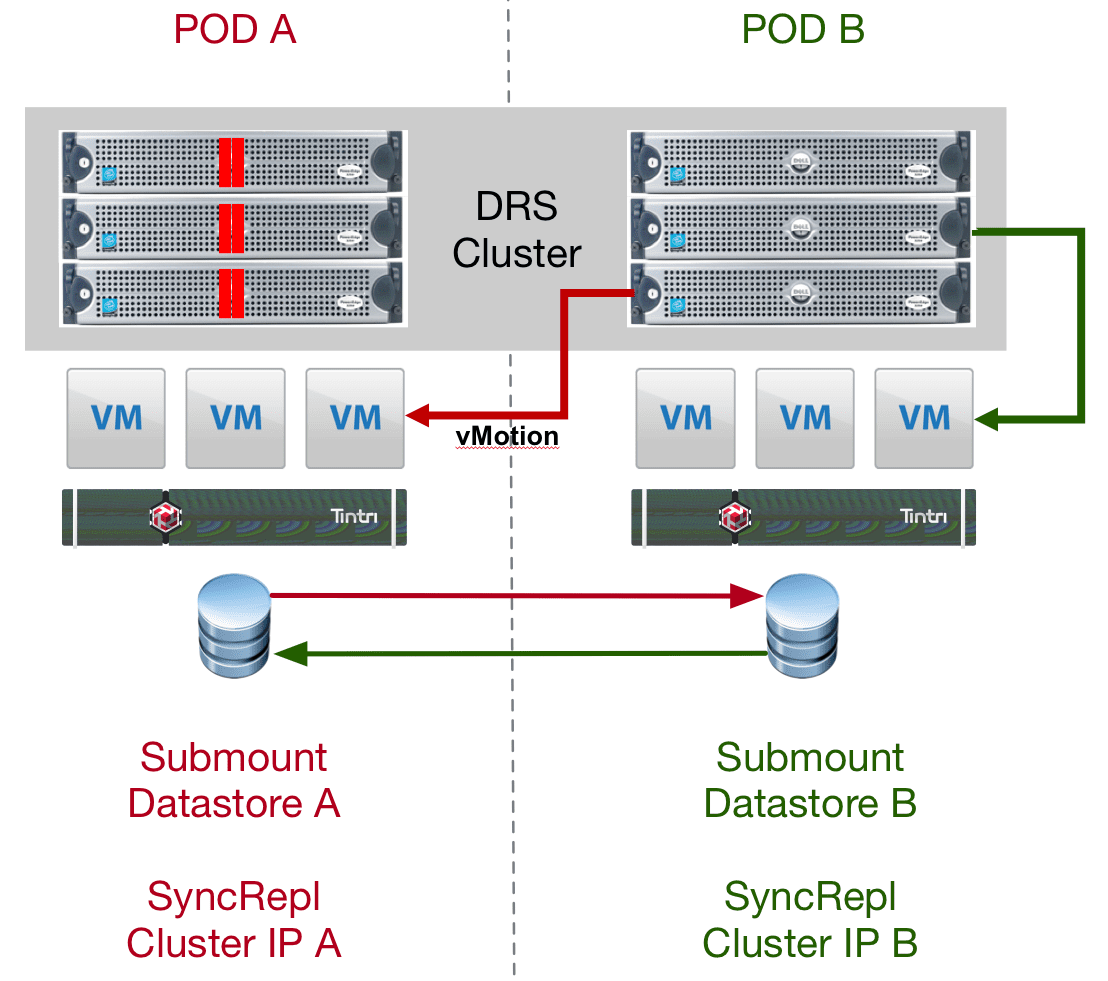
Once the vMotion is completed the hosts on the right side would be accessing the primary Tintri in the left cabinet. For a localized architecture this should not have much it any performance hit. If this was across town or campus that could be a design consideration in how long you run this way. Finally, if you invoke the manual failover of the Tintri Sync Replication group you would move the data path completely to the other side so now in fact you could do complete maintenance of the left side of the image, as everything we be free of traffic.
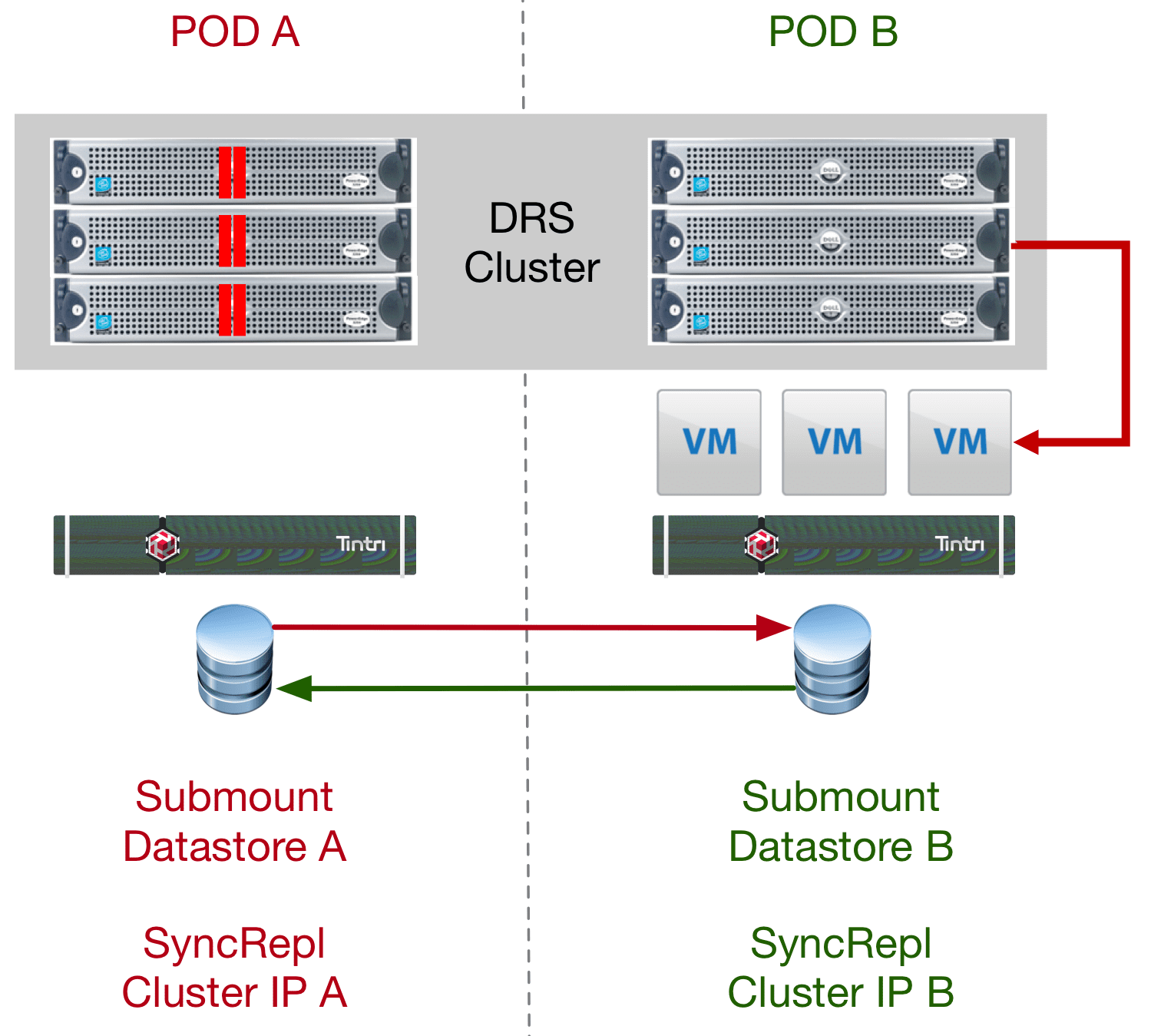
Does This Qualify as a vSphere Metro Cluster?
At this point technically no it does not primarily because the manual failover does not yet have an automatic option to work with Metro Cluster HA. However, Tintri is working on this as part of adding “automatic failover” to the sync replication groups in an upcoming release. At that point, we can test and demonstrate the High Availability portion of the design. Once both the DRS and HA aspect of the cluster can be fully supported and designed to work as a metro cluster, then you can call it that.
However, even at this stage the setup and simplicity of the replication group and the clusters to work at this level is very attractive. This design can be stood up in a very short time and utilized not only for this use case but a couple of others until the full Metro Cluster HA is made available.


