
![]()
I realized today that I have not actually blogged yet about the Tintri Synchronous Replication feature that was released a few months back. I decided to jump back into the lab to show people just how easy this is to use. What Tintri has built it’s base on has always been ease of use, and to be honest this feature is no different. Let’s take a look at just how easy it is to configure and use.
The Basic Steps
For you to configure and use Tintri Synchronous Replication, like the SRM setup I detailed previously it’s a few simple steps. This will require the use of Tintri Global Center 3.7 or higher to implement. I suggest you read the Tintri Global Center admin guide for latency requirements and other considerations.
- Create a Tintri Service Group using “Option 2”
- Mount the sub folder created on vSphere hosts
- Use the Cluster IP and sub folder path
- Move or deploy virtual machines to the datastore
- Monitor the groups replication in Tintri Global Center
Tintri Service Groups
The first thing to look at is something I wrote a couple of weeks ago to understand the difference between the Tintri Service Groups. The reason is there is some differences between how they are used and where they are configured. For the sake of this I will assume you’ve got the understanding of the different ones. Bear in mind Tintri is hoping to converge these in the future to make things easier. The first thing you need to do is create a new Tintri Service Group and run through the six simple steps. Remember this Tintri Service Group today cannot be used with SRM those are configured separately.
First just give the group a name
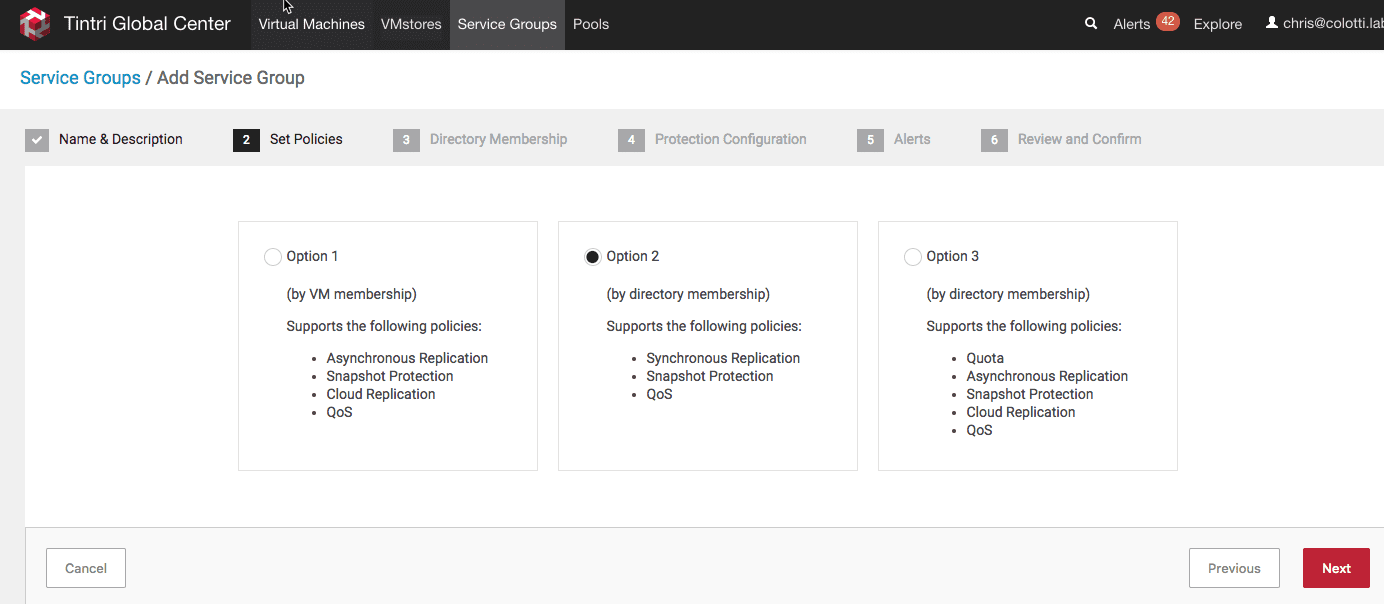
Then select “Option 2” for the synchronous replication
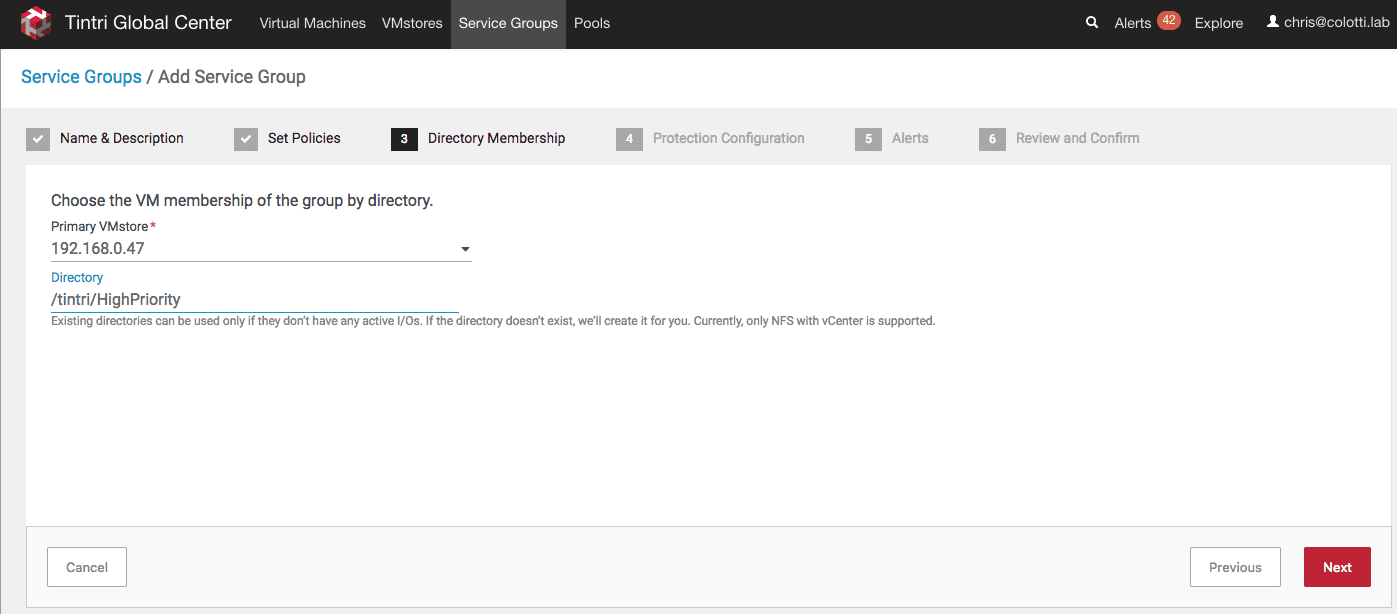
The next step is where you define a sub folder for the group to use as well as the PRIMARY VMstore. The folder will be created and we will use this later to mount as a datastore in vSphere. This folder will be created on both Tintri VMstores from this one screen.
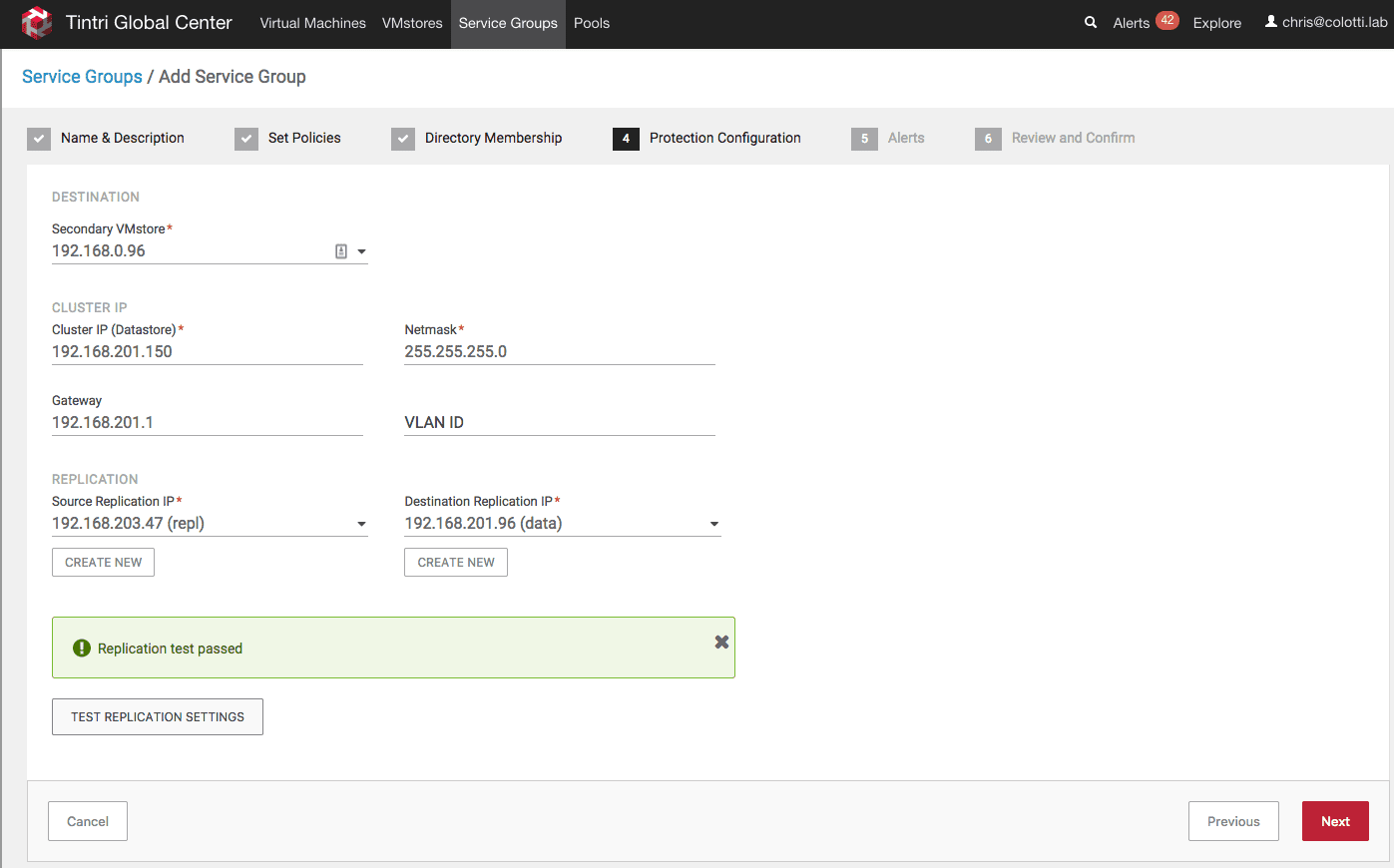
Here is where we setup the cluster configuration. We select the secondary VMstore and we assign a cluster IP address which should be on the Data network range. This cluster IP will be used to mount the previous sub folder as a new datastore. In my lab only one VMstore as a Replication IP, but ideally you would use both replication networks on both ends. in my case I am using the data network on the other side. Then you can test the settings.
We can just set some basic alerts
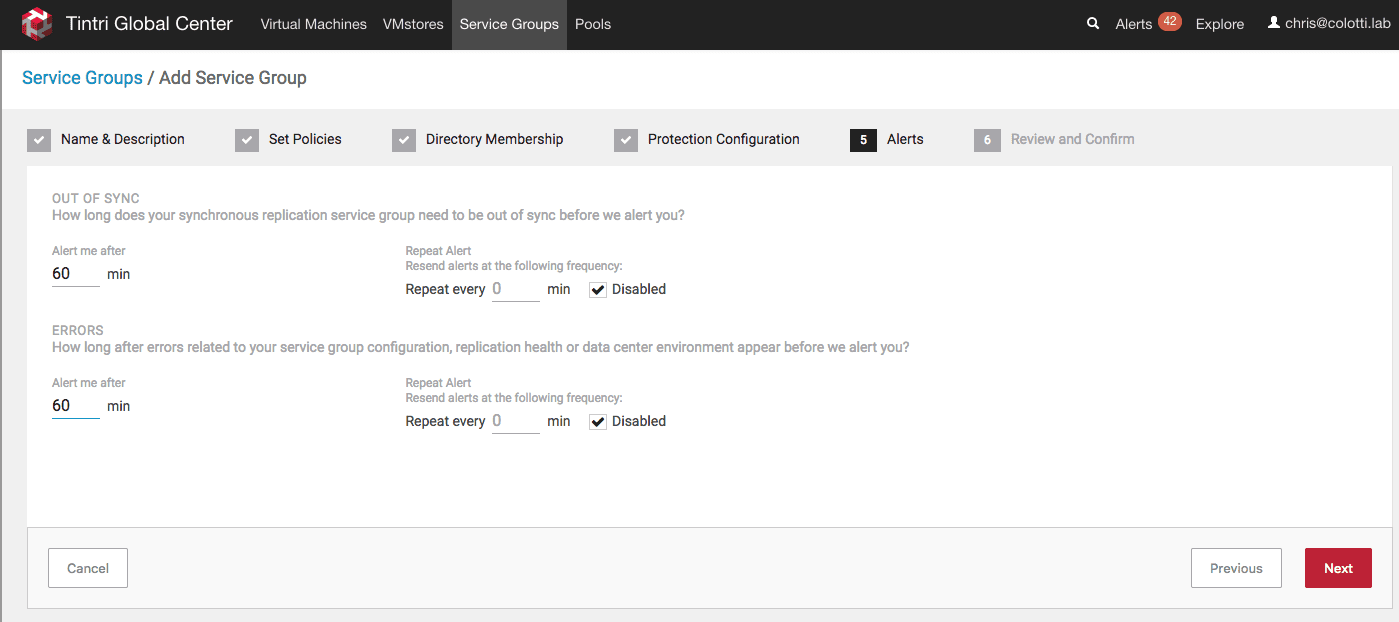
Finally review the settings and create the Tintri Service Group
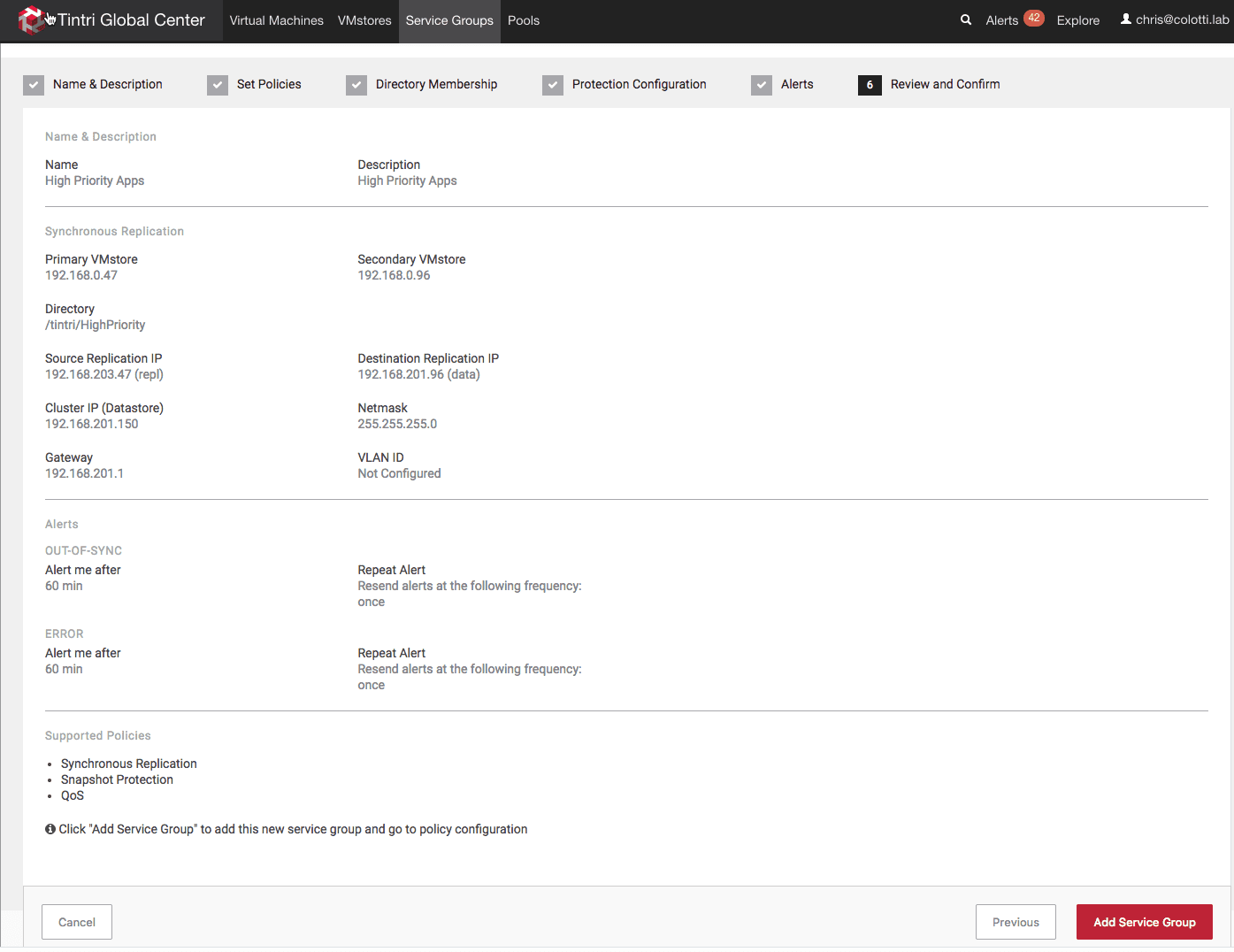
Once this is done the group will be created and do an initial setup. You can see the status of the group to check or modify settings or add snapshot protection as well to the group.
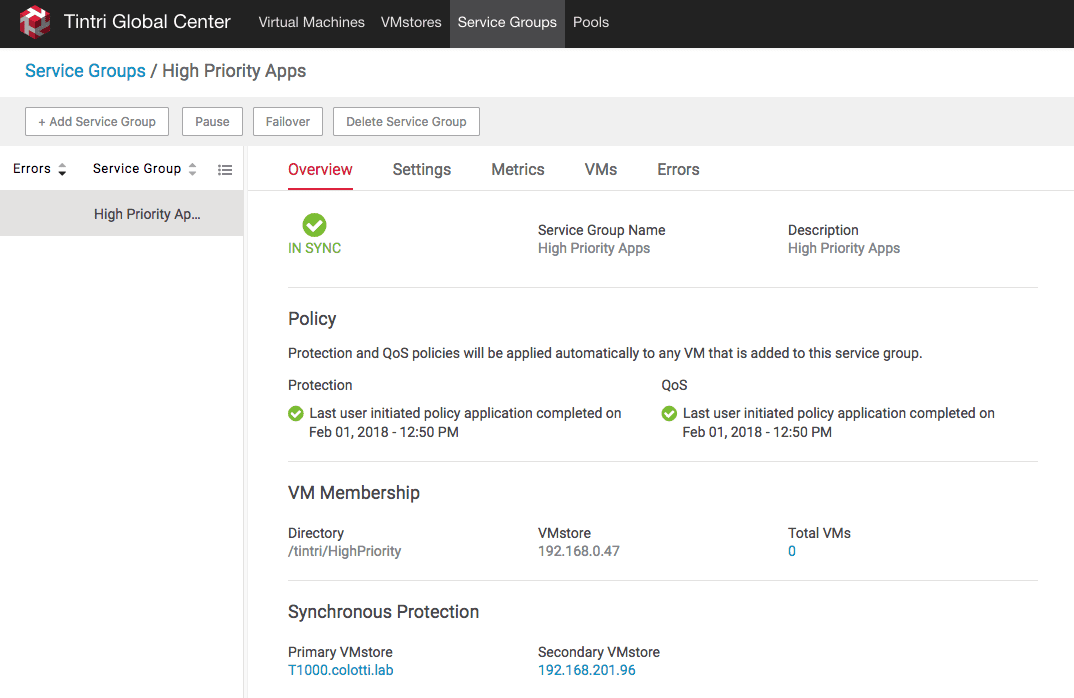
Using the new Service Group in vSphere
As I mentioned at the start once you setup this new “Cluster” you just need to present the new construct to vSphere. To do this you simply mount the datastore as a new NFS mount point. You will use the Cluster IP you created and the sub folder. I suggest you name the datastore to reflect the Tintri Service Group’s usage. This new datastore will effectively span both Tintri VMstores with the single namespace. While you can still deploy virtual machines to the base Tintri mount point those will not be replicated.
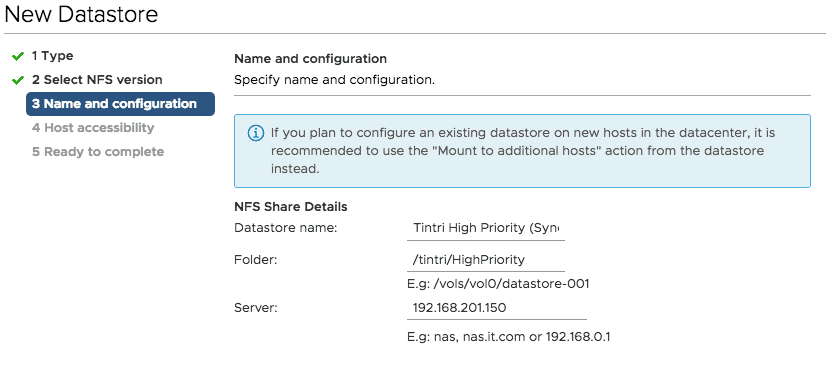
At this point you can migrate machines or deploy new ones to the new datastore and they will begin replication to stay in sync. One thing I will point out is that if you try to browse the sub folder on wither VMstore mounted directly in the default folder you won’t see anything. This is by design which is access denied, and the only way to see the virtual machine files is via the new datastore. At this point there is nothing you really need to do. You can pause replication or failover from the group settings. Here we can see there is one virtual machine in my new service group which was deployed to the new datastore.



