
In the past week there have been a rash of reports about people disabling VMware DRS, while vCloud Director was in place. I have tweeted multiple times about this and also brought it up on the Community PodCast yesterday. The more I bring it up the more people are asking why someone would do such a thing, and second what really happens. Well I wanted to take a moment to address both of these. First off the reason this is so important is that vCloud Director uses DRS Resource Pools to manage the Provider and Organization Virtual Datacenters. This is no secret, if you have played with the product and looked in vCenter you see a lot of resource pools. However if you have yet to install it now you know….vCloud Director relies on resource pools like it or not. I affectionately refer to the Allocation models as “Resource Pools Done Right”. Many have heard me say this at VMworld over and over.
Why Do Folks Disable DRS?
There are a few reasons why people completely disable DRS that I have seen. One is that this is a VMware GSS troubleshooting step, but GSS needs to be made aware you are running vCloud Director. If they know this going in I have been told they will not have you disable it. One other situation had a rogue vCenter administrator disable it because they were not aware that the cluster was managed by vCloud Director. This is one reason we all suggest a second, locked down vCenter, separate from one that many people may have access to. Prevention unfortunately is one of the keys here. The last is simply a “Clicked too fast” mistake when editing settings in vCenter. This is probably more common than you think it is, even some of the best people I know have made this mistake. If you need to prevent DRS moves simply change the setting to MANUAL, but please do not uncheck the box.
Isn’t There Any Kind of Warning?
Why yes there is! The screenshot is below. However it does not currently tie the warning to the fact you will completely break vCloud Director. This is something being looked at similar to the managed object warnings on the Virtual Machines themselves. The problem is people are still ignoring the message and continuing to do so
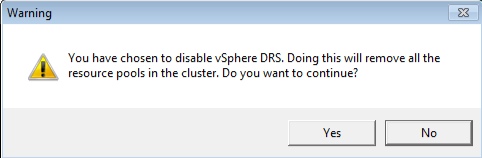
So What Actually Happens?
Without sugarcoating it…..pretty much everything in vCloud Director. This is where we get into the meat of the issue and you need some background. With vCloud Director, there is a separate database as we all know. This Database contains metadata and other information that ties back to vCenter UUID and MoREF information. Should these ID’s change in vCenter, vCloud Director’s Database does not know about the update. However if vCloud Director inserts an object it tracks them both. Think of this as a uni-directional update from vCloud Director to vCenter. We have always said changes made in vCenter are not always reflected in vCloud Director, so again this is no secret. Below is a simple config of one cluster that has a single Provider vDC and an Org vDC. There is also a vApp deployed to this Organization for argument’s sake.
 Now let’s disable DRS and see what happens in vCloud Director. As we expected the VM is still there and associated with vCloud as a managed object, but it is no longer associated with the Organization resources in any way. Imagine a large number of Organization vDC’s where all the vApp’s just get dropped to the root pool? No more service levels for all those paying customers for one!
Now let’s disable DRS and see what happens in vCloud Director. As we expected the VM is still there and associated with vCloud as a managed object, but it is no longer associated with the Organization resources in any way. Imagine a large number of Organization vDC’s where all the vApp’s just get dropped to the root pool? No more service levels for all those paying customers for one!

We also start seeing errors in vCloud Director for simple operations like powering on a Virtual Machine. We end up getting all kinds of angry errors, when we want to deploy a new vApp as well. You do get the detailed name of the resource pool that was removed. I think you get the point by now so I will not bother with more screen shots.
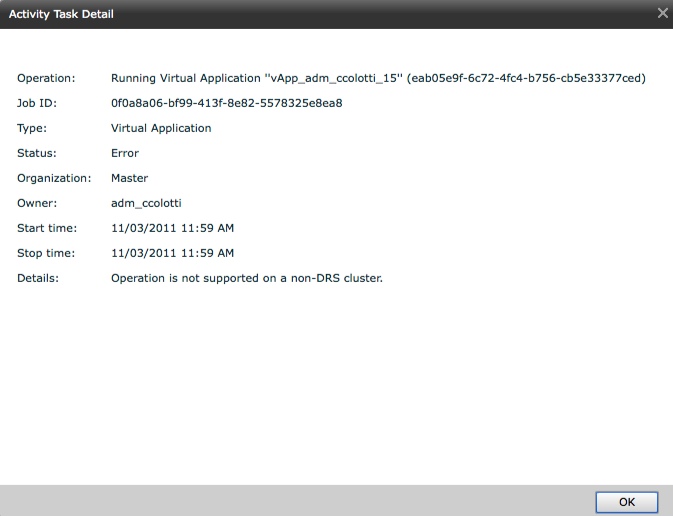
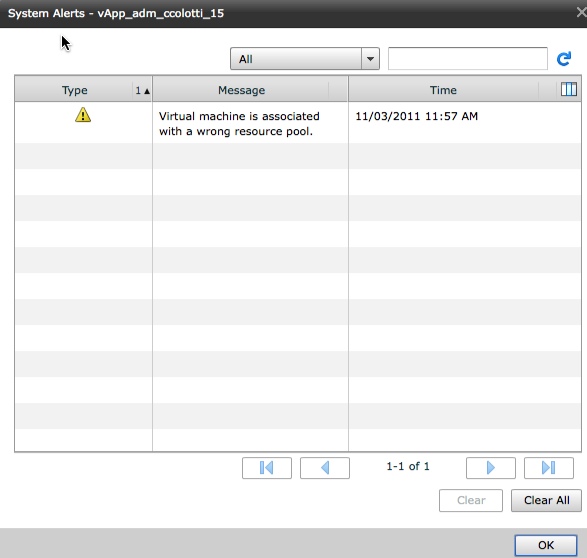
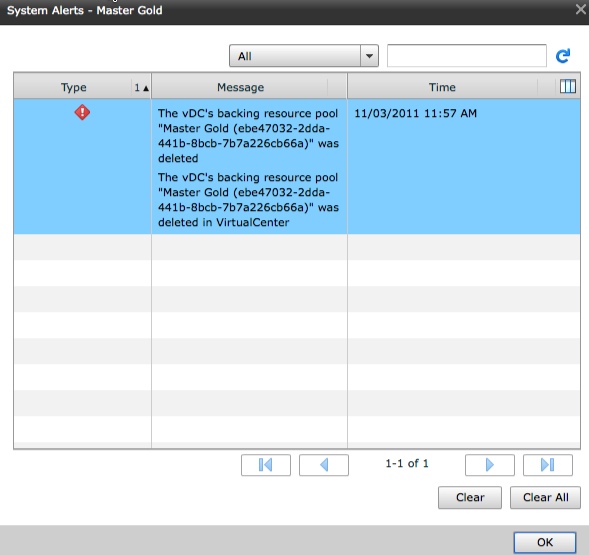
So How The Heck Do I Fix This!?
Well it is not easy, but it is also not impossible, and it is not really something you should do without GSS help. First thing is you need to re-enable DRS, and from there a lot of re-work will need to happen to re-create the Resource Pools and re-map them to the vCloud Director Database. This may not be as easy as it sounds, as you can see from the initial snapshot, the resource pool name also has a UID associated with it. You need to re-create them exactly as they were before the mistake was made. Again this is not for people to do on their own. I may try to play with this in my now broken lab to see if I can fix it, but I will NOT be posting the Database tables and other information should I get it to work. I’m not taking that responsibility should someone break something. The real issue is not for two pools, but what if you had 10, 50, or 100 to recreate? The whole time your users will not be able to do anything on the organizations and that is not good. You also have to know exactly where every Virtual Machine was associated with the right resource pool. Some of this may be in the vCloud Director Database as indicated by the error above. Obviously it is important to get each organizations Virtual Machines back to the right resource control. I have no idea how the ChargeBack data collectors will be affected by this either and what may happen to the billing reports. One other thing to consider is you have to also replace the “System vDC” as well but that gets created when you create a Provider vDC, but must also be re-created.
The Moral of The Story
Lock users out of changing this setting, with RBAC, or a completely separate locked down vCenter. Sometimes protecting people from themselves is the best option. If you do get into trouble call support, you are going to need them, and that is what they are there for. Just don’t do it, and think twice before you do. You can always set it to manual to prevent DRS migrations, but you need to maintain those Resource Pools. The thing to remember is that one way update from vCloud Director to vCenter, and it is not currently the other way around. I am currently working on investigating ways this, and other use cases where MoREF ID’s have changed in vCenter can be recovered, but it will take some time and possibly tools like vCenter Orchestrator for example. There is also a VMware Labs Fling for Inventory Snapshot, which I have yet to test to see if it recreates with the original MoREF ID’s, but I plan on seeing the results this coming week.



Hi Chris,
thanks for taking my thread from the forums and explaining things a little more detailed.
I just tested the Inventory Snapshot script, but unfortunately it doesn’t work 🙁
Resource Pools and folders are created without any problems, but the MoREF ID’s seem to mismatch or some other problem prohibits the creation of new VMs via vCD.
Maybe the script can be edited so the IDs are taken care of during the process.
I will happily test anything in my lab.
Well it is a “Fling” so I am not sure if I can get anyone to edit it. I suspected the inventory may have been preserved, but it re-creates the pools. I doubt we can create objects with specific MoREF ID’s, but I am looking into if we can update the vCD DB, (With some level of support help), to pickup the new ones. Of course this is just one use case where ID’s change, so I am looking at the bigger picture.
http://www.vpaule.de/index.php/disabling-drs-or-ha-will-kill-your-vcloud-director/
Like I have said before, Just don’t do it 🙂
If only you would have said this a few days earlier 😉
Thanks for having taken your time to explain all this. This will help many the way it has helped me.
You know chris a few things come to mind in this….
Knowledge is power people need to be educated in general when working with VCD… the large question is that there should be *some* integration of VCD with the vCenter attached in a way to where this just is NOT possible… It’s almost like VMware doesn’t want to make the effort to avoid its own problems…
There are a few other issues in general as well as you stated… Some enterprises cannot afford the added cost of dedicated vcenters for certain implementations I mean alot of companies try to do cloud on a lower scale. Sometimes its just not reasonable though it is easily justifiable… We do have it separated out – MGMT cluster and then PROD cloud cluster. I may share our design some time in the future. This makes me wonder if we should just lock down the vCloud vCenter completely. I am going to have to share my thoughts over on my blog in further detail… reading your blogs have kind of opened up my eyes… especially from an architect stand point ;).
Oh and on a seperate note this is why its important to have a BU/DR solution that integrates with VCD – like Veeam – I know shameless plug but the best thing in the worst situations is a DR – you should probably note this as well… just a suggestion..
It sure seems like there is (or maybe was) a severe lack of synergy between the vCD team and the vSphere team during development of vCD given all these “whoops” type scenarios that exist between vSphere and vCD. I hope that gap has since been filled. Things like this should just NOT be possible. You bringing this to everyone’s attention is much appreciated.
Whats more interesting is that there is a bigger gap in the folks running it then VMware in some way. Just a personal opinion of mine. I also have to say that in the referenced VCAT stuff for vCloud it covers it pretty well. Though, Chris does an excellent job of brining it up and addressing it more thoroughly. 🙂
Hi Chris,
Thanks a lot for your very detailed post.
Quick question for you : does disabling HA has an impact on vcloud Director ?
Thanks.
I would not say it has a DIRECT impact, but as you have read it has an IN-Direct impact in the way it affects the Cluster backending the Provider vDC